今天繼續訓練階段中的模型評估。
給定一個資料集(英、中文平行語句),為了 LSTM seq2seq 模型在該資料集上的翻譯能力表現,我們依序進行下列任務:
translated_sentence = pred_seq(model, single_seq_pair, reverse_tgt_vocab_dict)
for i in range(n_samples):
# extract true pair of sentences
src_sentence, tgt_sentence = seq_pairs_input[i]
# lists translation results of first five sentences
if i < 5:
print("source: {}\ntarget: {}\ntranslated: {}".format(src_sentence, tgt_sentence, translated_sentence))
corpus_bleu(true, predicted, weights = (w1, w2, w3, w4))
將整個流程整理起來以定義下列函式:
def eval_NMT(model, X_input, seq_pairs_input, reverse_tgt_vocab_dict):
"""
Evaluates trained NMT model on a given dataset
------------------------------------------------
X_input:
[a few enc_inputs, a few dec_inputs]
date type: numpy array of shape: [(n_sentences, src_max_seq_length), (n_sentences, tgt_max_seq_length)]
seq_pairs_input:
source and target sentences
data type: list of list of strings
"""
# Step 0: Check shape and specify max_seq_length
print("shape of src_seqs: [{}, {}]".format(X_input[0].shape, X_input[1].shape)) # [(8000, 13), (8000, 22)]
true, predicted = [], []
src_max_seq_length = X_input[0].shape[1]
tgt_max_seq_length = X_input[1].shape[1]
# Step 1: Translate each sentence
for i in range(X_input[0].shape[0]): # 8000
# Step 2: Prepare training data of one sample (current sentence)
single_seq_pair = [X_input[0][i].reshape(1, src_max_seq_length), X_input[1][i].reshape(1, tgt_max_seq_length)]
# src_seq shape: [(?, 13), (?, 22)]
# Step 3: Predict a single sample and creates a string of tokens
translated_sentence = pred_seq(model, single_seq_pair, reverse_tgt_vocab_dict)
# Step 4: Collect ground truth sentences and predicted sentences
src_sentence, tgt_sentence = seq_pairs_input[i]
# lists translation results of first five sentences
if i < 5:
print("source: {}\ntarget: {}\ntranslated: {}".format(src_sentence, tgt_sentence, translated_sentence))
true.append([tgt_sentence.split()])
predicted.append(translated_sentence.split())
# Step 5: Calculate corpus BLEU scores on the dataset X_input
## Individual n-gram scores
print("Individual 1-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 0, 0, 0))))
print("Individual 2-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (0, 1, 0, 0))))
print("Individual 3-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 1, 1, 0))))
print("Individual 4-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 0, 0, 1))))
## Cumulative n-gram scores
print("Cumulative 1-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 0, 0, 0))))
print("Cumulative 2-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (.5, .5, 0, 0))))
print("Cumulative 3-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (.33, .33, .33, 0))))
print("Cumulative 4-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (.25, .25, .25, .25))))
# evaluate model on training dataset
eval_NMT(eng_cn_translator, X_train, seq_pairs, reverse_tgt_vocab_dict)
# evaluate model on training dataset
eval_NMT(eng_cn_translator, X_test, seq_pairs, reverse_tgt_vocab_dict)
我們透過在訓練資料集上檢視模型的 BLEU 分數來評估其翻譯能力: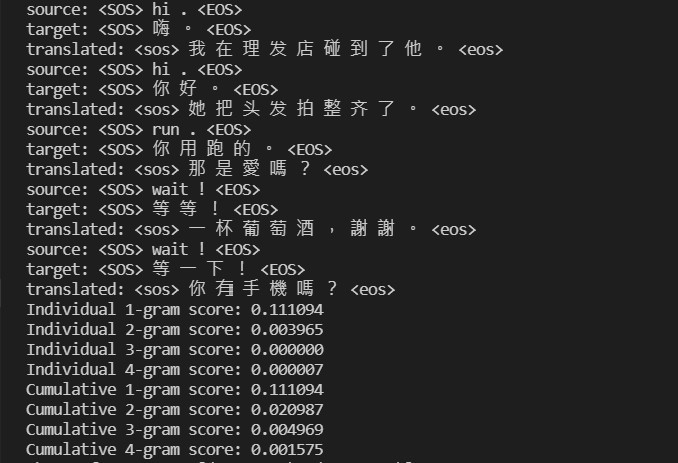
接著在測試資料集上評估結果: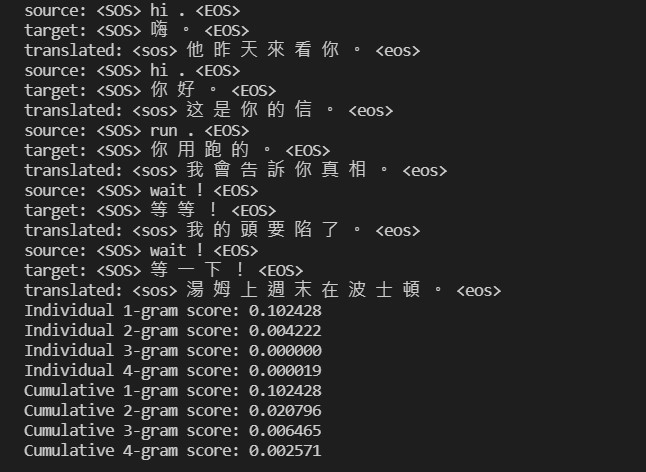
瀏覽了一下發現各個 N-grams 的 corpus BLEU 分數很低,讓我不禁懷疑模型準確度是否極低下。
給定模型與資料集,以下函式將會從資料集中隨機抽出一筆樣本進行翻譯,來檢視英文原文並比對中文原文以及中文譯文:
import random
def translate_rand_sentence(model, X_input, reverse_tgt_vocab_dict):
"""
Translates a sentence at random in a specified dataset
"""
src_max_seq_length = X_input[0].shape[1]
tgt_max_seq_length = X_input[1].shape[1]
i = random.randint(0, X_input[0].shape[0] - 1)
# ground truth sentences
print("actual source sentence: {}".format(' '.join([reverse_src_vocab_dict[id] for id in X_input[0][i] if id not in [0, 1, 2]])))
print("actual target sentence: {}".format(''.join([reverse_tgt_vocab_dict[id] for id in X_input[1][i] if id not in [0, 1, 2]])))
# translated sentence
one_seq_pair = [X_input[0][i].reshape(1, src_max_seq_length), X_input[1][i].reshape(1, tgt_max_seq_length)]
print("predicted of NMT model: ", (''.join(pred_seq(model, one_seq_pair, reverse_tgt_vocab_dict).split()).lstrip("<sos>")).rstrip("<eos>"))
縱使 BLEU 分數不高,我們還是實際讓模型在測試資料上隨機抽選樣本進行翻譯,並檢視翻譯文句與真實文句之間的差異程度:
translate_rand_sentence(eng_cn_translator, X_test, reverse_tgt_vocab_dict)
前兩次翻譯皆有一字之差:

這次終於完全翻譯正確了(淚
後來我發現了 corpus BLEU 低下的原因在於我選定的文本特徵 X_input 與原始句對 seq_pairs_input 並不匹配,真是個天大的烏龍。因此明天會接著繼續 debug ,各位晚安。

